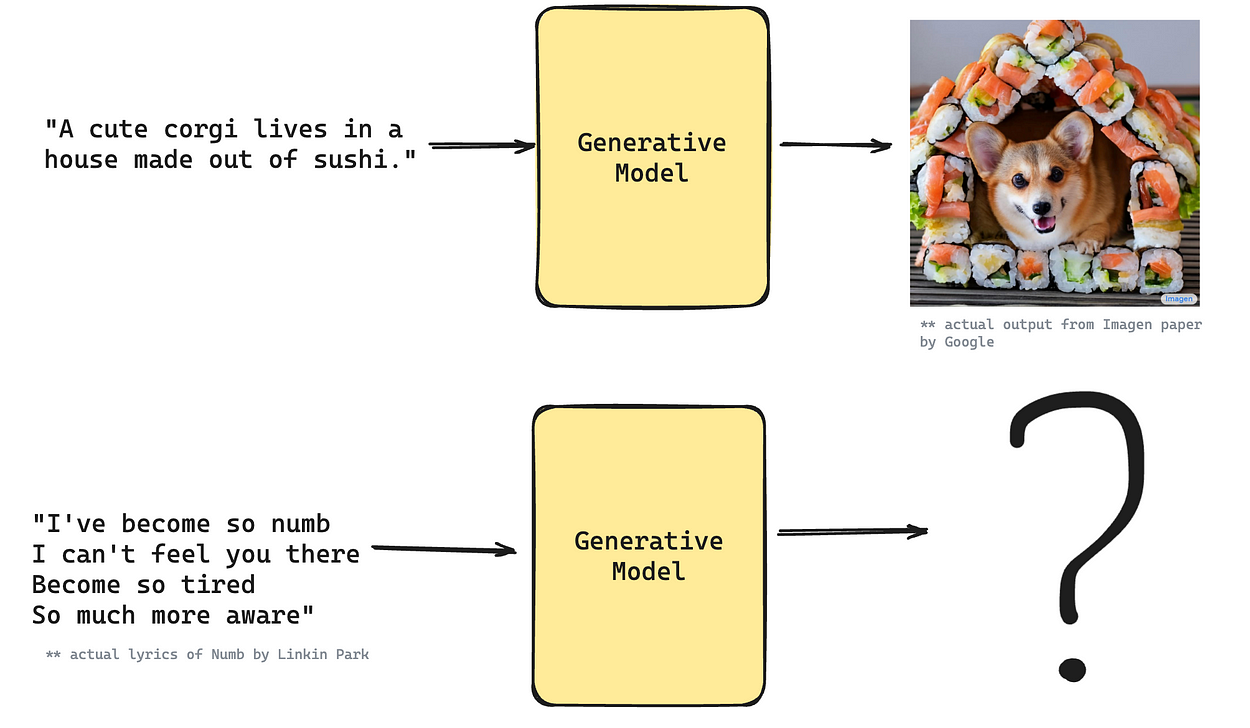
Supercharging generative models with Music!

A high-quality dataset is a significant factor that influences the efficacy of well-known generative AIs like Dall-E, GLIDE, etc.. LLM models like CLIP made substantial progress in image-text understanding due to the 400 million image-text pairs used for training (and, of course, its novel architecture). So, we all can agree that finding a suitable dataset is a crucial process for model development!
While most of these generative models are trained on vast datasets of textual or visual modalities, none (to the best of my knowledge) are currently trained on auditory data, like Music, something so personal to a user in today’s age of entertainment. Thus, after months of drudgery, our team at Blitzfa eCommerce has finally released a new multimodal dataset for everyone utilizing Music in their research/application. We’re so thrilled to share what it consists of. We call it — LAG (Lyric-Audio-Genre)!
But wait! There are other music datasets already; what’s new in LAG?
The MSD (Million Song Dataset) is a well-known and publicly available dataset. It contains metadata for about a million songs and looked perfect for our use case until we discovered the dataset is no longer maintained. Due to that, much of the dataset’s documentation is in multiple places. Moreover, the data available to download on the site is distributed in different files, so consolidating them may take some time. Lastly, it doesn’t contain music lyrics or audio features: this was a huge drawback for us as our problem statement involved identifying the relationship between different music attributes. Nevertheless, we still highly recommend you check out the MSD site once. (https://millionsongdataset.com/)
The following dataset we referred to was the DEAM dataset, which consists of 1802 excerpts and full songs, annotated with valence and arousal values continuously (per second) and over the whole piece. This dataset is appropriate for sentiment analysis of Music as it provides the valence and arousal features over a portion of the song. However, it still leaves our wants unanswered; it doesn’t have lyrics or audio features. (https://cvml.unige.ch/)
To coda, no unified dataset currently offers a combination of lyrics, audio, audio features, and genre information in one place. This scarcity inspired us to create one to use for our generative applications. We spent several months experimenting with this dataset using different state-of-the-art generative models and developing our own. (which we’ll be releasing soon, so stay tuned for that!)
Our novel dataset is manually compiled and verified. This guide will provide a detailed understanding of how it uses audio to give a newer approach to art generation.
So, without further ado, let’s jump in!
LAG — what is it?
Our new dataset, LAG, contains 663 samples packed in a pickle file (.pkl), each containing five features as given below:
-
fileName: name of the audio sample used [string] -
lyrics: as present in the respective audio sample, to the nearest word (manually verified) [string] -
mfcc: using FFMPEG, mfcc of the actual audio files were extracted to a size of (55168,) [vector of shape (55168,)] -
genre: describes the genre of the audio sample, limited to ‘metal’, ‘rnb’, ‘pop’, and ‘rap’ [string] -
genreIdx: label encoded value of the genre, useful for classification purposes. [number — metal ⇒ 0 | pop ⇒ 1 | rnb ⇒ 2 | rap => 3]

Snapshot of the dataset, presented as a data frame. [Source: Author]
To zoom in, one such data point in our dataset would look something like this:
[
"out_Can_you_hear_me_Vanden_Plas_0_2",
"We had all the gods among us",
[
-291.4468078613281,
-239.32164001464844,
-228.03614807128906,
-252.06797790527344,
-231.99853515625,
-191.72869873046875,
-202.8234405517578,
-231.3618927001953,
-254.9090576171875,
-275.6394958496094,
-228.58197021484375,
-185.22433471679688,
-215.76168823242188,
-286.9477233886719,
-273.1100769042969,
-265.9569091796875,
-272.7559509277344,
-279.12506103515625,
-193.7666778564453,
-120.65702056884766,
-106.29338073730469,
-126.46701049804688,
-147.24468994140625,
-167.37974548339844,
-181.86651611328125,
...
-37.49418258666992,
-33.93297576904297,
-31.638160705566406,
-31.275402069091797,
...
]
"metal",
0
]
Dataset Characteristics — a little on our recipe!
The proposed dataset was curated from a set of metal, rnb, pop and rap audio songs, each split into the 10s, up to a total of 90s (i.e., 10 x 9), giving nine samples per audio file.
These audio samples were then processed to extract their MFCC features using Librosa (a Python package for Music and audio analysis). MFCC, or Mel-Frequency Cepstral Coefficients, is a compact representation of audio signals in a way that captures the unique traits of the audio, like timbre and pitch. Moreover, it’s processed on a scale (i.e., Mel scale) at which we humans perceive audio. Hence, MFCC is a suitable vector-like representation for processing audio. A snippet of the relevant code is given below:
path = "path to audio file"
y, sr = librosa.load(path)
mfccs = librosa.feature.mfcc(y=y, sr=sr, n_mfcc=2048)
We selected the n_mfcc hyper-parameter 2048, which gave us the shape of (54656,). This shape was not arbitrarily chosen; the input shape required for our model was (65536,). We kept the number of n_mfcc as 2048, as we wanted the maximum shape for the embeddings, which we then processed to get the required shape for our model, but delineating that is beyond the scope of this guide.
Lastly, the audio sample’s corresponding lyrics were compiled manually (to the nearest meaningful sentence). So, the corresponding lyric is an empty string for the audio samples that only have instrumental notes. All this data was amalgamated into a single pickle file (.pkl).
The main feature of our dataset is the availability of lyrics and audio-extracted MFCC features in one file. This dataset would assist other fellow researchers in finding the relationship between a song’s lyrics and its audio features (which essentially encapsulates the mood and essence of the audio sample).
Data Quality and Exploration
Our dataset comprises 663 data points belonging to four genres: metal, rnb, pop, and rap (we’ll be expanding on this soon). The distribution of the genre count is nearly identical, as you can see:
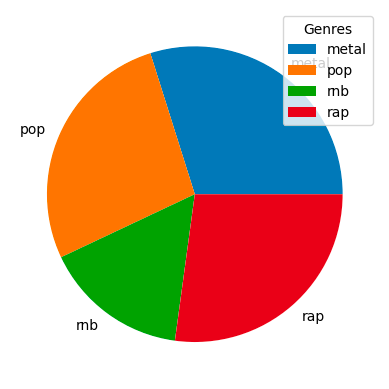
We went with metal, rnb, pop, and rap genres first because our application required working with lyrical audio samples primarily. In contrast, genres like jazz focus more on the song’s rhythm, valence, and arousal. A few selected genre songs only had instrumentals in selected portions, and the corresponding lyrics were kept empty. To better understand this, refer to the diagram below:
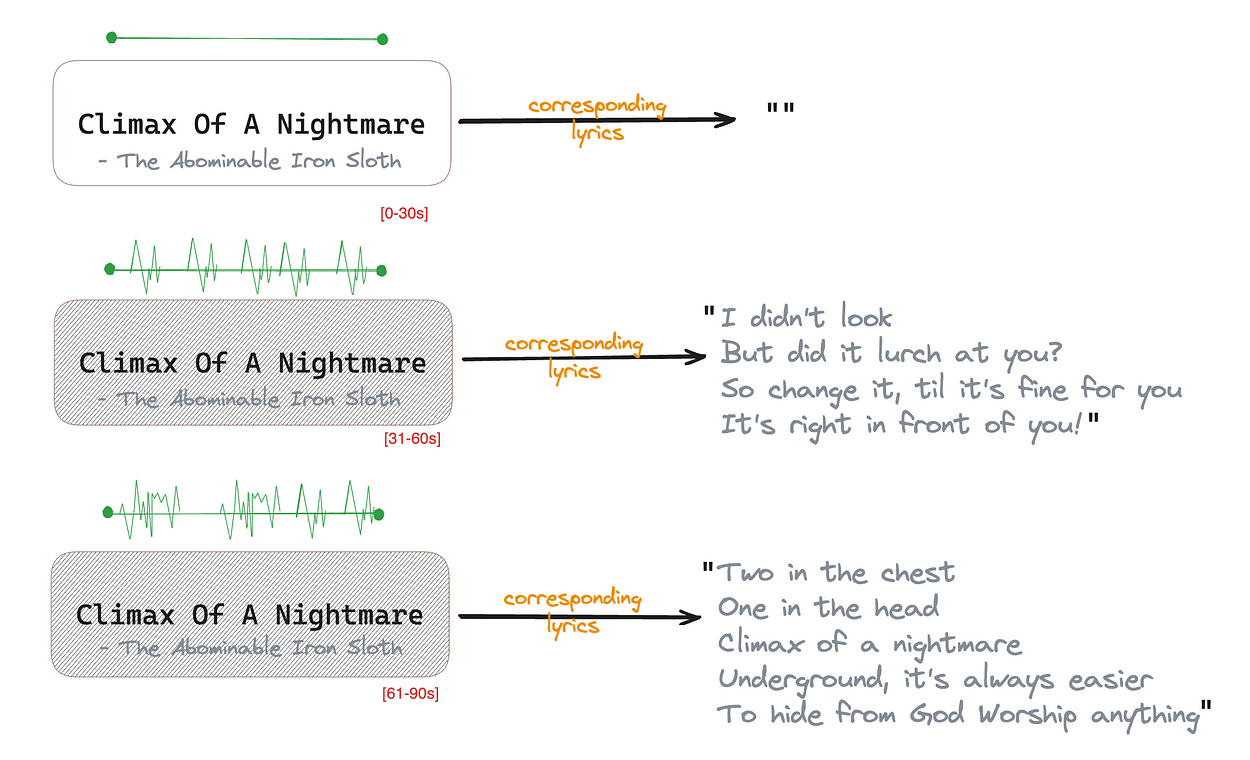
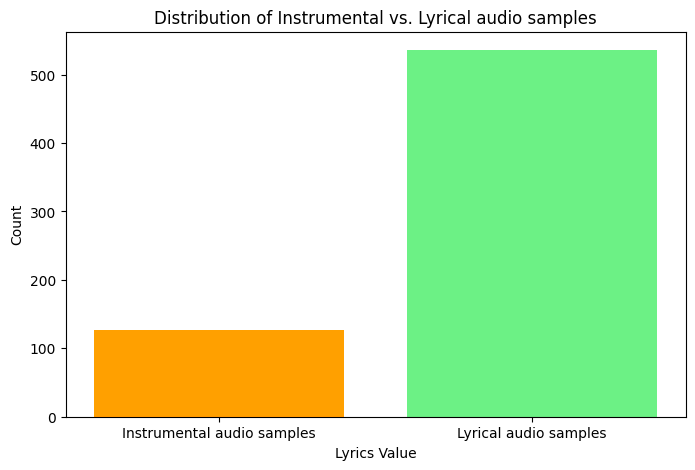
Therefore, should you be interested in working with it, our dataset contains many audio samples containing some lyrics and a few instrumental audio samples. Refer to the diagram below for our current distribution between instrumental and lyrical audio samples.
Our dataset’s unique thing is that it consists of an audio sample’s lyrics and other features, like song embeddings. This opens a lot of scope for researching how lyrical prompts can influence art generations (as was in our case) using the same audio-extracted MFCC features. From most of our experimentation with SOTA models and our custom architecture of generative models, having longer textual inputs (of lyrics) seemed suboptimal. We surmise that longer lyrics, which are already abstract when taken out of context, increase the level of abstract components in the mix. There are many ways to circumvent this, and one of the solutions we found is a no-brainer. We empirically found that shorter-length prompts provide much more intuitive results, and therefore, we focused on gathering shorter-length prompts in our dataset.
Let’s see how lyrical values change across different genres to understand more about the word count distribution.
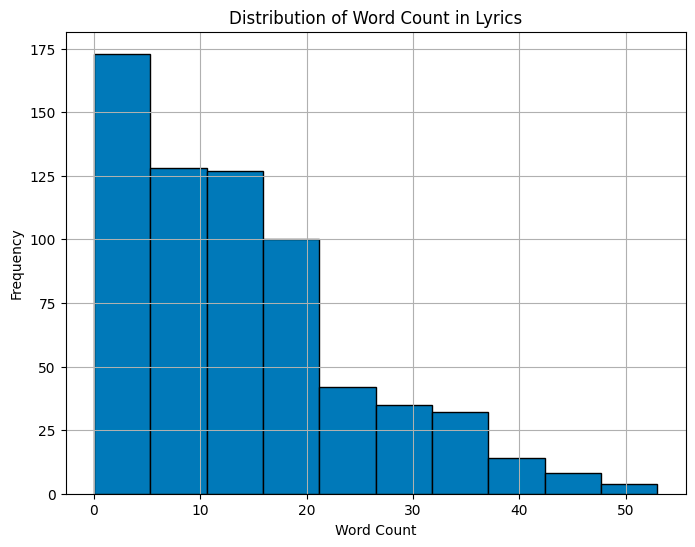
From the above graph, we can infer that most lyrics have 0–5 words on average throughout the dataset. The rest of the majority is in the bins of 5–15 words
Comparing it on a per-genre basis, we can see the distribution across all our genres except rap is nearly identical (see figure below).
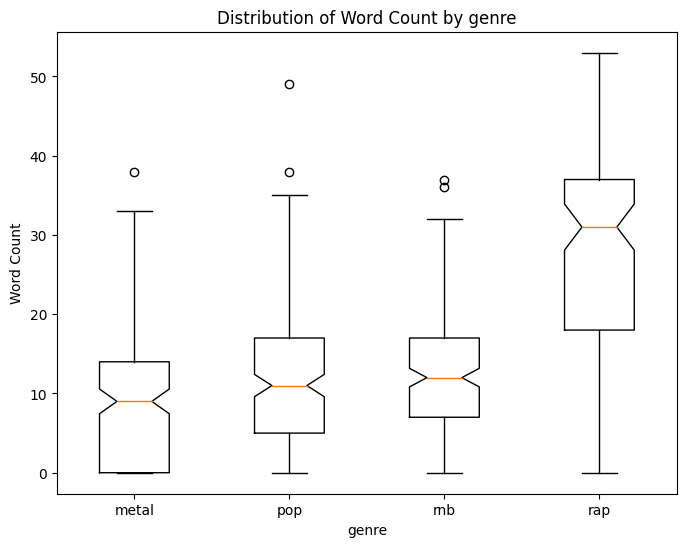
From the boxplot above, we drew the following inferences:
- Metal has more samples in the range of 0–5 word count. This suggests that it has more number of instrumental audio samples.
- Pop and RnB have nearly identical distribution, mainly in the 5–15 word range, suggesting fewer instrumental-only samples belong to this genre.
- The metal genre has the highest inter-quantile range (IQR) and the highest median as well. This suggests that most of the audio samples have a more significant number of words (i.e., 20–35), as rap music tends to have a faster lyrical flow.
These findings support our histogram above, stating that the word count in our dataset skews to the left, peaking in the lower word ranges. This is crucial information when working with LLMs, as most LLMs have a specific token limit to the input size it can encode — CLIP’s limit is 77 tokens. This makes our dataset compatible with most of the LLMs; the limit of 10s to each audio sample was influenced majorly by this limitation of LLMs.
Potential Applications
Assuming you now have a gist of the dataset, let's understand one of the applications that best suits this dataset: Art Generation using Music!
None of the current art generation experiments involve the interplay of audio or even music lyrics for generative applications. Usually, they take in a descriptive prompt, which provides a detailed layout of what the image should be. This is not the case when it comes to lyrics and Music, which are abstract and written to evoke a certain mood.
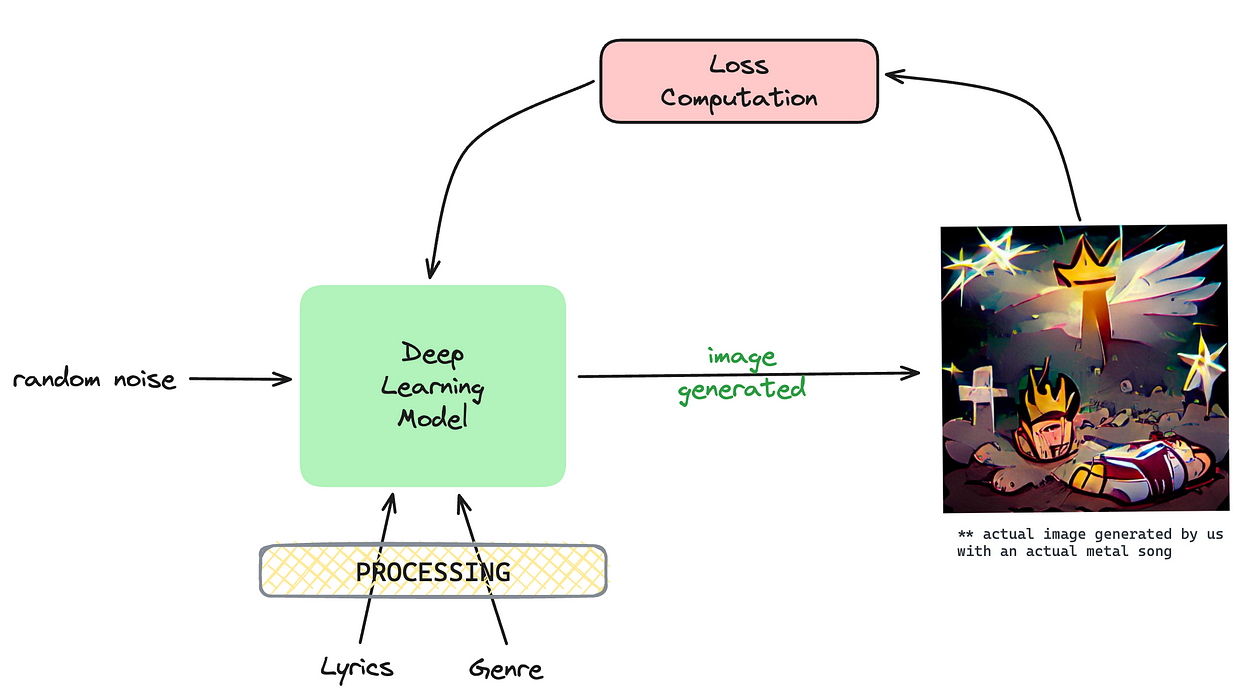
Our multimodal architecture utilizes our LAG dataset to incorporate all these features plus more with a vision to find a link between the art generated with the audio, its features, lyrics, mood, and genre. Let’s look at an oversimplified version of the research we are currently working on (we’ll soon be releasing a detailed article addressing this research using the same dataset).
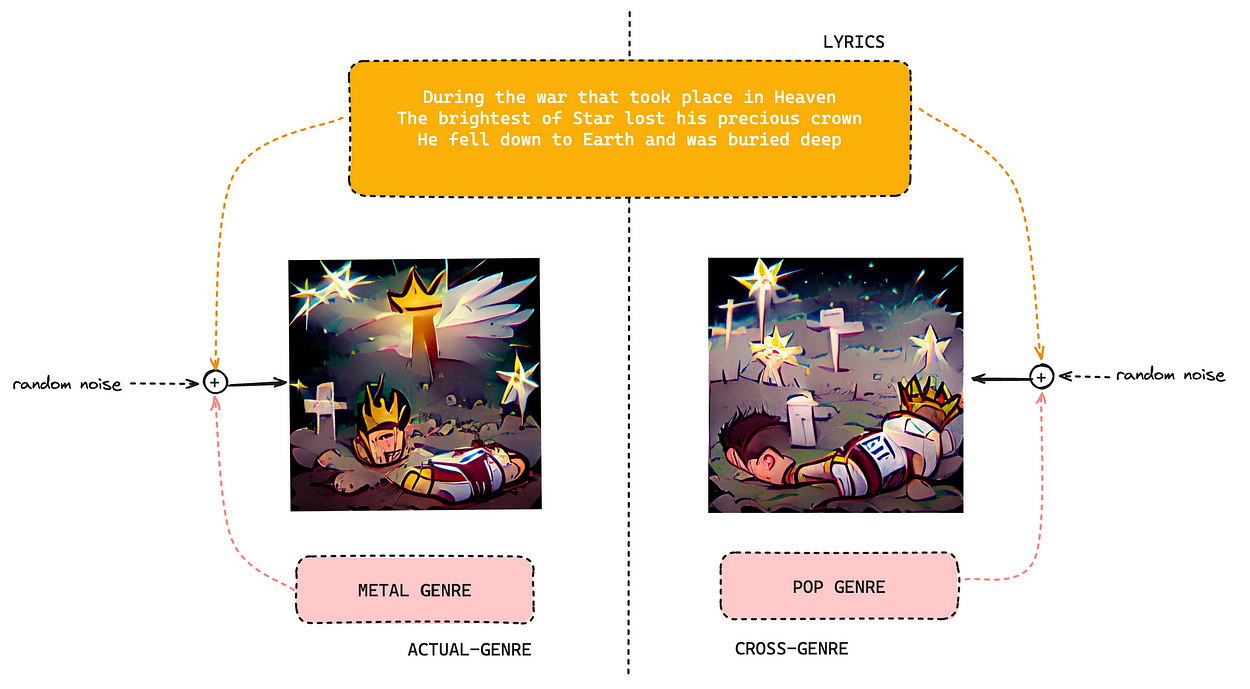
Not only this, but our dataset also provides interesting results for cross-pollination in support of adding meaningful details to the abstract art. To give a gist, we cross-pollinated the same lyric and MFCC features with different genres to identify the nuances, and the results were worthwhile to decipher.
In addition to that, we also experimented with how the addition of MFCC features makes a difference.
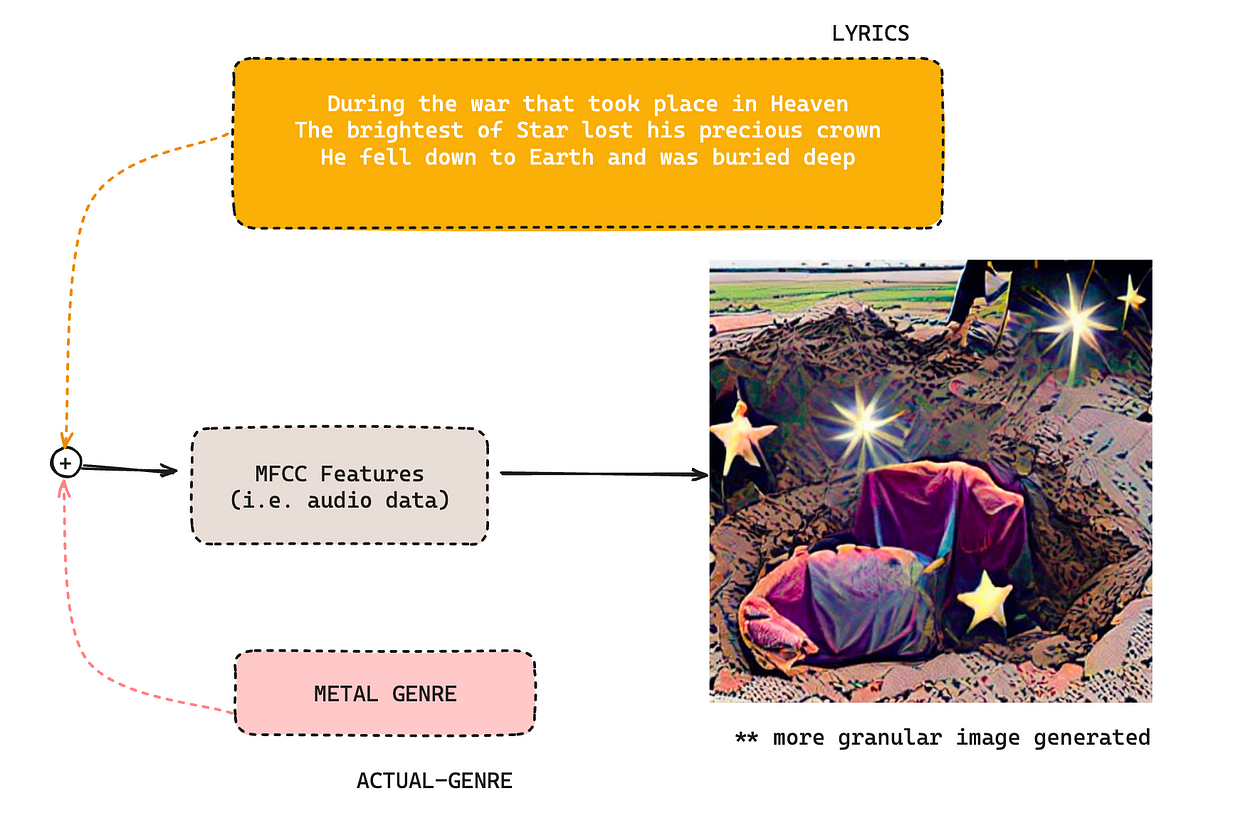
Adding the MFCC features (i.e., audio features) adds granularity to the output and produces a more realistic image than animated ones (as we saw earlier). This opens us to a new level of research and experimentation of including audio features in image generation. Stay tuned for more releases!
This is just one of the many applications our dataset supports. Feel free to experiment with it and tag Blitzfa on LinkedIn while you are at it.
Data Availability and Accessibility
The dataset is available at Blitzfa’s GitHub as the first release and is open to everyone. We encourage anyone using this dataset to kindly attribute/mention our team on LinkedIn so we can spotlight you on our Github’s README. (Dataset link)
Final words
While we are excited to see how we can further expand this dataset, we do have some of our visions that we have set, especially with our research on art generation using music. If you’d like to know more about it, stay tuned!