
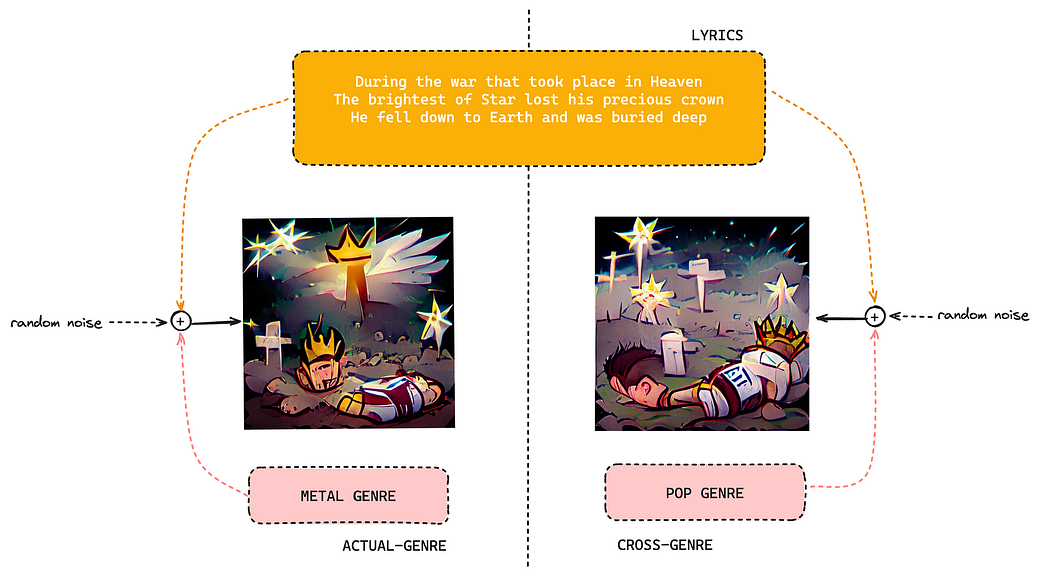
In the realm of AI-generated content, the fusion of different modalities like images and text has opened up exciting possibilities. For instance, now we can generate images from textual inputs using Diffusion models or even realistic minute logn videos using SORA from OpenAI. However, none of the implementations, to the best of our knowledge, work well with abstract elements like lyrics. For instance, the output generated by Stable Diffusion 2 on a metal genre music just takes the textual input as is.

Hence, our initial surmise is that state-of-the-art models aren’t catered to capture the abstractness present in music and it’s lyrics yet. This is exactly what Blitzfa is openly propelling towards!
Recently, we introduced the LAG dataset, a rich resource containing music features paired with lyrics and genre information. Leveraging this dataset, we strived to train various multimodal architectures right out-of-the-box and futher tweaked them upon analysing the outcomes. One such multimodal architecture we examined was VQGAN-CLIP.
Giving a gist of VQGAN-CLIP
VQGAN-CLIP is a powerful combination of generative and discriminative AI wherein the VQGAN component of the model is responsible of generating an image from latent space (mostly Gaussian noise or the encoded output of a VAE). The image generated is then encoded by CLIP to compare the distance between the image embeddings and the embeddings of the input text provided by the user (i.e. prompt), giving us contrastive loss.
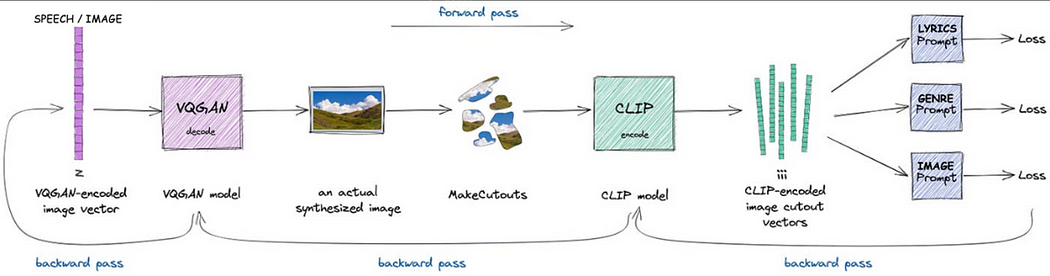
While we are in the process of experimentation, we observed something quite interesting that was worth sharing with the community online and that’s the focus of this blog.
Something intriguing…
One of the pivotal experiments we conducted involved integrating our own attention mechanisms into the architecture to create a more refined output. We came about this hypothesis because the outputs we generated had a tinge of animated feel, taking away the wrath of metal music or the bop-energy of pop music.
By incorporating attention layers into the input prompt, we aimed to capture the nuances and context embedded within the lyrics. We experimented with both multi-head and Bahdanau attention mechanisms, each offering unique insights into the interplay between words and their relevance.
Upon training the attention layers and then inferencing with the same input parameters, the outputs were interesting to look at.
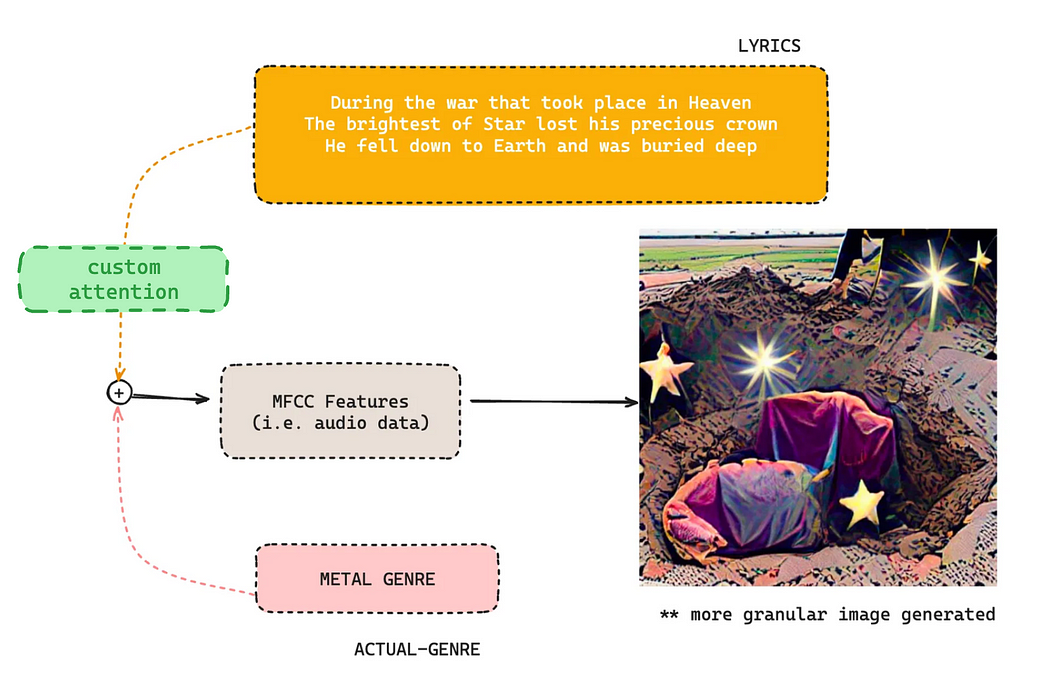
As we can see, the output generated is a less cartoon-ish right now. We can see the sand grains. Moreover, it also encapsulates the burried deep down part quite well. Upon closer inspection, we can notice there’s a shovel like object at the top left which it generated poorly.
This output was interesting to analyze as none of this was mentioned in the input. The entire essence of the lyric and it’s corresponding music snippet corresponds to a scene of statement in any superhero movie. The audio evokes a strange emotion of defeating anyone in your path (at least for me). The entire point of audio-based generation is that it’s subjective, which makes it quite challenging. Hence, from the above experiment, we understood that using a custom attention layer was necessary for adding a touch of “reality” to the output. The attention layers were trained with CLIP LOSS in a way that it gives more weightage to the genre. The following diagram should clear things up for you.
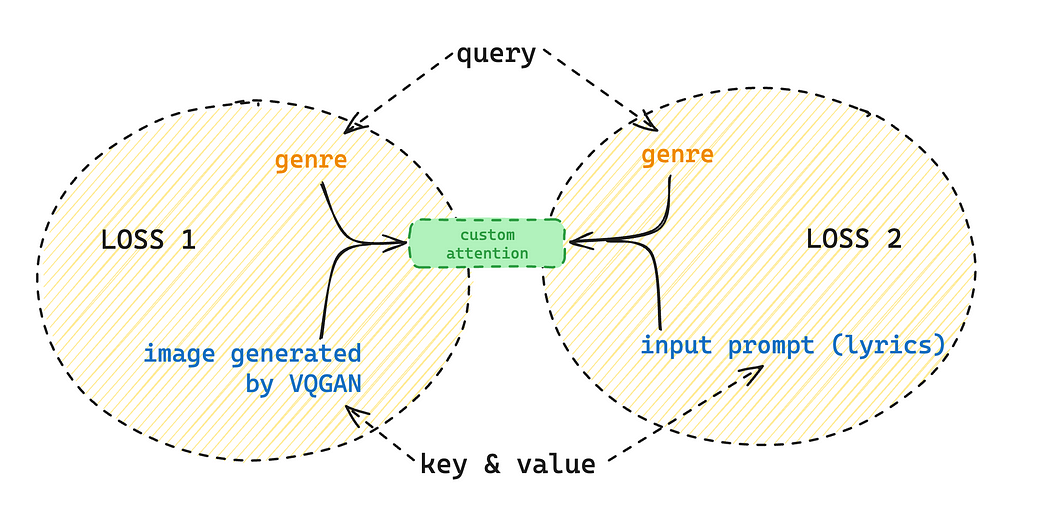
Custom Attention Layers, when trained properly, can be used to chain different layers of complexity to your output.
While this is just the tip of the iceberg of what we have found, we’ll be releasing more of our findings as we go forward. If you’d like to keep in touch with our journey, please subscribe to our Medium to be notified when our next blog comes up.