This story covers how Blitzfa caters to thousands of users for its custom AI model service, VanGO, using a relatively new cloud infrastructure: Beam.
With the release of VanGO, users have been swarming our servers to generate graphics based on their ideas and chosen music. VanGO is an innovative arcitecture developed by Blitzfa that allows users to generate images by combining their ideas and styling them with their own choice of song. While AWS SageMaker was initially our platform of choice, it quickly became apparent that its limitations were a significant barrier to maintaining both system stability and performance. Between maintenance downtimes, slow deployments, and frustrating scalability issues, we needed to act swiftly. The solution? Beam Cloud, a new infrastructure offering, that has alleviated the pain points previously associated with SageMaker!
For a long time, developers across the industry have relied on AWS SageMaker to deploy custom machine learning models. SageMaker offers a platform where custom binaries, model weights, and inference code can be uploaded, enabling developers to expose models as endpoints ready for production (or prod-like) usage. In theory, this should work seamlessly. Upon uploading to SageMaker, developers essentially expose an endpoint to their custom model, which can then be attached to literally ANYTHING — in our case, our Indusvale website.
However, as we scaled VanGO and encountered the high demands of user traffic, SageMaker’s inadequacies became glaringly evident. SageMaker’s integration with AWS Lambda enforces a strict 60-second timeout on requests, which was increasingly problematic for our use case. Many of our models, including complex ones involving large, convoluted neural networks or fine-tuned models with custom LORA weights, simply could not meet this threshold.
Not only that, we faced several other issues with Sagemaker when deploying bespoke models, or models pulled from Hugging Face, or even a traditional model with custom LORA weights.
Issues with AWS:
Let’s break down the specific technical hurdles we faced with SageMaker and why they ultimately pushed us to seek out a more reliable alternative.
#1. The infamous: Worker Thread Died.
Well, we weren’t the first to encounter this and that’s for obvious reasons.
Deploying MLLM and other large architectures has often been a hit-or-miss situation, based on our experience. We frequently found ourselves debugging why our model worked yesterday but not this morning. Such instability led us to recreate fresh Docker images, redeploy ECRs, and then deploy to AWS, hoping it would be in a good mood.
Despite deploying with high hopes, SageMaker often threw us into an unpredictable state of deployment failures. The error we encountered most often was the dreaded “worker thread died” issue. This typically occurred during the deployment of larger models or after a configuration update. The real cause of it remains an open-ended question. Some attribute it to module incompatibility, while others point to incorrect usage of “accelerate.” It becomes more of a frenzy in the deployment logs, where the error messages are terse and vague.
One can’t rely on deploying large models to SageMaker when you have such an unstable deployment pipeline.
To make things more interesting, we also wanted to incorporate on-demand serverless inference to automatically spin up and down instances during periods of activity and inactivity, respectively, thus providing us with a cost-effective solution. However, the unstable nature of SageMaker worker threads, which essentially manage your processes, left us in a state of flux. It didn’t give us the confidence that if our model was up now, it would be up after a cold boot as well. For such reasons, we couldn’t even make our solution cost-effective. This was another straw in the pile of inconvenience.
Don’t get us wrong — bugs and errors are a part of a healthy development lifecycle, especially when you, as a developer, have the flexibility to control the moving parts, with promise. We were never assured that our model, given its sheer size and complexity, would be up at any given time. Stack Overflow and GitHub issues often pointed to incompatibility between PyTorch versions, accelerate, and some other modules, but they worked perfectly well on EC2 instances. Never mind that; we did go about tweaking modules, and that introduced another pain point.
#2. Recreate ECR for new modules and new tar files for any minute change?!
One of the most tedious and time-consuming aspects of deploying on SageMaker was the requirement to constantly rebuild and redeploy entire container images. Whenever we had a new model, a minor code update, or even a small change in one of our dependencies, we were forced to rebuild and push a new Docker image to Amazon Elastic Container Registry (ECR). This was especially cumbersome for any incremental change, no matter how trivial.
A common argument I often encounter with the community is that it provides you with the flexibility to deploy anywhere, and I wholeheartedly agree. Dockerizing your code is a great way to distribute across multiple VMs and endpoints, as it makes your model resource-agnostic. However, pushing to ECR and, at times, committing new modules can take quite a long time. Sure, there are a few workarounds, but for a fast-moving startup, you need something more efficient.
Beam Cloud: The Solution We Needed
Beam Cloud, on the other hand, streamlined the deployment process significantly. With features like auto-scaling, flexible model hosting, and robust resource management, Beam eliminated the pain points we faced with SageMaker. The new deployment workflow, which does not require constant rebuilding of container images for each change, vastly improved our turnaround time. Additionally, Beam’s ability to efficiently manage resources like GPUs, memory, and storage in a more intelligent and dynamic way has resolved the out-of-memory and timeout issues that plagued our previous setup.
I mean, just look at this piece of code:

That’s all you need to define your working environment. Beam has been a game changer for us, as it takes the load off of us from an infrastructure point of view and lets us focus on real development, which is important.
To further support my point about why we chose Beam, allow me to illustrate how we are using Beam for our newly limited-access, VanGO
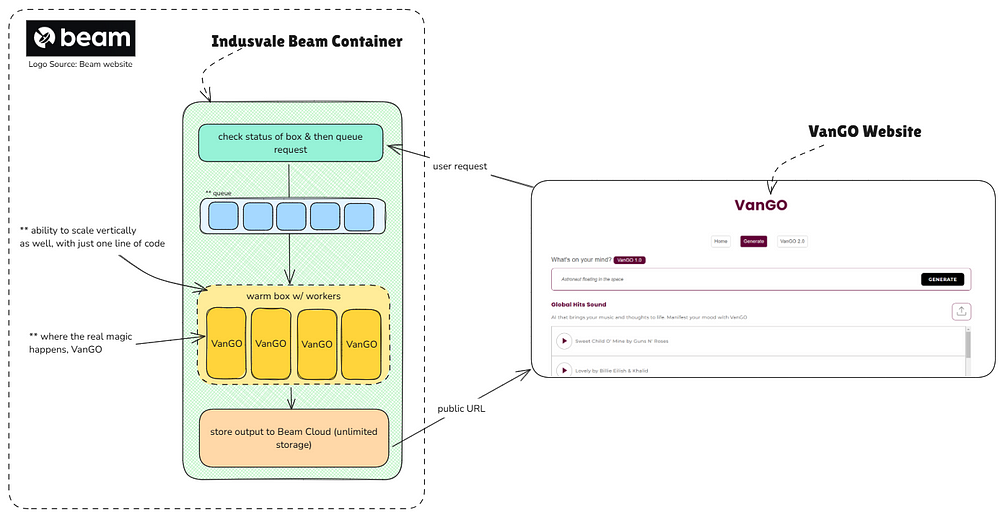
With Beam, we have:
- one-click deployment solution
- ability to modify the Python runtime env via the code
- more stable deployments
- more user-intuitive DevOps
- lastly, and more importantly, it’s cheaper :)
and don’t take our word for it, compare your prices as well.
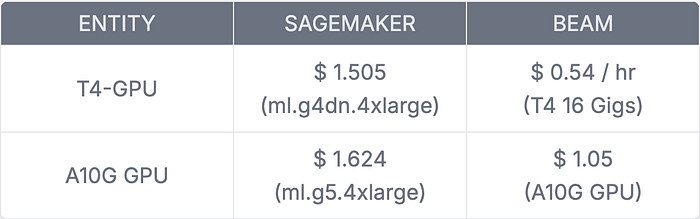
Conclusion:
In conclusion, while SageMaker is a robust tool for many developers, it was not the right fit for Blitzfa’s growing needs. As we scaled VanGO, SageMaker’s limitations became increasingly evident, prompting us to seek out an alternative. Beam Cloud’s flexibility, scalability, and reliability provided the solution we were looking for, and it has now become our go-to platform for deploying custom AI models.
Moreover, just a side note: this is in no way intended to defame any service. This is more of a personal experience and simply us following one of our core values — to be transparent and contribute to a healthy community by sharing what we discover!